一.服务器规划
192.168.4.116 hadoop-namenode # 该节点只运行namenode服务
192.168.4.135 hadoop-yarn # 该节点运行resourcemanager服务
192.168.4.16 hadoop-datanode1 # 数据节点
192.168.4.210 hadoop-datanode2 # 数据节点
192.168.4.254 hadoop-datanode3 # 数据节点
二.服务器优化
1.安装前准备
Java 8+, Python 2.7+/3.4+, R 3.1+,Scala 2.11及hadoop3.1.1
操作系统:CentOS Linux release 7.3.1611 (Core)
内核: 4.19.0-1.el7.elrepo.x86_64
Jdk版本号:1.8.0_20
Hadoop版本号:3.1.1
Scala版本号:2.12.8
Spark版本号:2.3.2
2.升级Centos7内核
具体实验步骤:
# 载入公钥
rpm –import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
# 安装ELRepo
rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm
# 载入elrepo-kernel元数据
yum –disablerepo=\* –enablerepo=elrepo-kernel repolist
# 查看可用的rpm包
yum –disablerepo=\* –enablerepo=elrepo-kernel list kernel*
# 安装最新版本的kernel
yum –disablerepo=\* –enablerepo=elrepo-kernel install -y kernel-ml.x86_64
# 重启操统系统
reboot
# 删除旧版本工具包
yum remove kernel-tools-libs.x86_64 kernel-tools.x86_64
# 安装新版本工具包
yum –disablerepo=\* –enablerepo=elrepo-kernel install -y kernel-ml-tools.x86_64
#将新安装的内核设定为操作系统的默认内核,或者说如何将新版本的内核设置为重启后的默认内核
grub2-set-default 0
grub2-mkconfig -o /etc/grub2.cfg
# 再次重启操统系统
reboot
至此,已完成升级
#查看发行版本
cat /etc/redhat-release
#查看内核版本
uname -r
3.设置静态IP
#启动网卡
systemctl start NetworkManager
systemctl enable NetworkManager
systemctl status NetworkManager
systemctl restart NetworkManager
#操作
nmcli con show
nmcli con mod ‘Wired connection 1’ ipv4.method manual ipv4.addresses 192.168.4.135/24 ipv4.gateway 192.168.4.1 ipv4.dns 8.8.8.8 connection.autoconnect yes
nmcli con mod ‘Wired connection 1’ ipv4.method manual ipv4.addresses 192.168.4.16/24 ipv4.gateway 192.168.4.1 ipv4.dns 8.8.8.8 connection.autoconnect yes
nmcli con mod ‘Wired connection 1’ ipv4.method manual ipv4.addresses 192.168.4.210/24 ipv4.gateway 192.168.4.1 ipv4.dns 8.8.8.8 connection.autoconnect yes
nmcli con mod ‘Wired connection 2’ ipv4.method manual ipv4.addresses 192.168.4.116/24 ipv4.gateway 192.168.4.1 ipv4.dns 8.8.8.8 connection.autoconnect yes
nmcli con mod ‘Wired connection 2’ ipv4.method manual ipv4.addresses 192.168.4.254/24 ipv4.gateway 192.168.4.1 ipv4.dns 8.8.8.8 connection.autoconnect yes
nmcli con reload
5.禁用selinux
setenforce 0
sed -i ‘s/SELINUX=enforcing/SELINUX=disabled/’ /etc/selinux/config
6.优化内核参数
vim /etc/sysctl.conf
#增加内容如下所示:
net.ipv4.icmp_echo_ignore_all = 0
net.ipv4.tcp_fin_timeout = 2
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_max_tw_buckets = 5000
net.ipv4.tcp_syn_retries = 2
net.ipv4.tcp_synack_retries = 2
net.ipv4.tcp_max_orphans = 2000
net.ipv4.tcp_max_syn_backlog = 4096
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 65536 16777216
net.ipv4.ip_local_port_range = 5000 65000
net.core.netdev_max_backlog = 1000
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.nf_conntrack_max = 25000000
net.netfilter.nf_conntrack_max = 25000000
net.netfilter.nf_conntrack_tcp_timeout_established = 180
net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120
net.netfilter.nf_conntrack_tcp_timeout_close_wait = 60
net.netfilter.nf_conntrack_tcp_timeout_fin_wait = 120
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
执行sysctl -p 生效
7.修改hostname
hostnamectl set-hostname hadoop-namenode –static
hostnamectl set-hostname hadoop-yarn –static
hostnamectl set-hostname hadoop-datanode1 –static
hostnamectl set-hostname hadoop-datanode2 –static
hostnamectl set-hostname hadoop-datanode3 –static
8.SSH免登录置(此一步可以使用“四.安装hadoop”第7点方法处理,如果此处已处理,在“四.安装hadoop”第7点方法处理这一步略过,不需要操作)
#各个节点执行生成公私钥
ssh-keygen -t rsa
cat /root/.ssh/id_rsa.pub >> /root/authorized_keys
#在hadoop-namenode-192.168.4.116上
scp -p ~/.ssh/id_rsa.pub root@192.168.4.16:/root/.ssh/authorized_keys
scp -p ~/.ssh/id_rsa.pub root@192.168.4.135:/root/.ssh/authorized_keys
scp -p ~/.ssh/id_rsa.pub root@192.168.4.210:/root/.ssh/authorized_keys
scp -p ~/.ssh/id_rsa.pub root@192.168.4.254:/root/.ssh/authorized_keys
#在hadoop-yarn-192.168.4.135上
scp -p ~/.ssh/id_rsa.pub root@192.168.4.16:/root/.ssh/authorized_keys
scp -p ~/.ssh/id_rsa.pub root@192.168.4.116:/root/.ssh/authorized_keys
scp -p ~/.ssh/id_rsa.pub root@192.168.4.210:/root/.ssh/authorized_keys
scp -p ~/.ssh/id_rsa.pub root@192.168.4.254:/root/.ssh/authorized_keys
#在hadoop-datanode1-192.168.4.16上
scp -p ~/.ssh/id_rsa.pub root@192.168.4.116:/root/.ssh/authorized_keys
scp -p ~/.ssh/id_rsa.pub root@192.168.4.135:/root/.ssh/authorized_keys
scp -p ~/.ssh/id_rsa.pub root@192.168.4.210:/root/.ssh/authorized_keys
scp -p ~/.ssh/id_rsa.pub root@192.168.4.254:/root/.ssh/authorized_keys
#在hadoop-datanode2-192.168.4.210上
scp -p ~/.ssh/id_rsa.pub root@192.168.4.16:/root/.ssh/authorized_keys
scp -p ~/.ssh/id_rsa.pub root@192.168.4.116:/root/.ssh/authorized_keys
scp -p ~/.ssh/id_rsa.pub root@192.168.4.135:/root/.ssh/authorized_keys
scp -p ~/.ssh/id_rsa.pub root@192.168.4.254:/root/.ssh/authorized_keys
#在hadoop-datanode3-192.168.4.254上
scp -p ~/.ssh/id_rsa.pub root@192.168.4.16:/root/.ssh/authorized_keys
scp -p ~/.ssh/id_rsa.pub root@192.168.4.116:/root/.ssh/authorized_keys
scp -p ~/.ssh/id_rsa.pub root@192.168.4.135:/root/.ssh/authorized_keys
scp -p ~/.ssh/id_rsa.pub root@192.168.4.210:/root/.ssh/authorized_keys
9.处理ping回路127.0.0.1和自己本机内网IP不通问题
#临时开启
echo 0 > /proc/sys/net/ipv4/icmp_echo_ignore_all
#永久开启
echo “net.ipv4.icmp_echo_ignore_all = 0″>>/etc/sysctl.conf
sysctl -p
三.安装jdk1.8
yum install lrzsz wget vim -y
#上传jdk1.8压缩包
rpm -qa | grep openjdk
yum -y remove java-*
tar -xvf jdk-8u20-linux-x64.tar.gz
rm -f jdk-8u20-linux-x64.tar.gz
#编辑jdk环境变量
vim /etc/profile.d/java.sh
#添加内容如下所示:
#!/bin/bash
JAVA_HOME=/data/jdk1.8.0_20/
PATH=$JAVA_HOME/bin:$PATH
export PATH JAVA_HOME
export CLASSPATH=.
#授权
chmod +x /etc/profile.d/java.sh
source /etc/profile.d/java.sh
#查看jdk版本
java -version
四.安装hadoop
1.新增用户hadoop
groupadd hadoop
useradd -g hadoop -s /usr/sbin/nologin hadoop
2.为hadoop用户增加管理员权限,方便部署,避免一些对新手来说比较棘手的权限问题
visudo
#在root ALL=(ALL) ALL下面增加一行
hadoop ALL=(ALL) ALL
3.为了测试方便,会关闭所有服务器的防火墙,在所有服务器上执行关闭防火墙
systemctl stop firewalld # 停止firewall
systemctl disable firewalld # 禁止firewall开机启动
firewall-cmd –state # 查看默认防火墙装状态(关闭后显示notrunning, 开启显示running)
4.关闭所有服务器的SLNEX
vim /etc/selinux/config
#修改内容为
SELINUX=disabled
5.修改hostname
vim /etc/hostname
#新增内容为
hadoop-namenode #其它分别为hadoop-yarn,hadoop-datanode1,hadoop-datanode2和hadoop-datanode3
6.配置hosts
vim /etc/hosts
#新增内容为
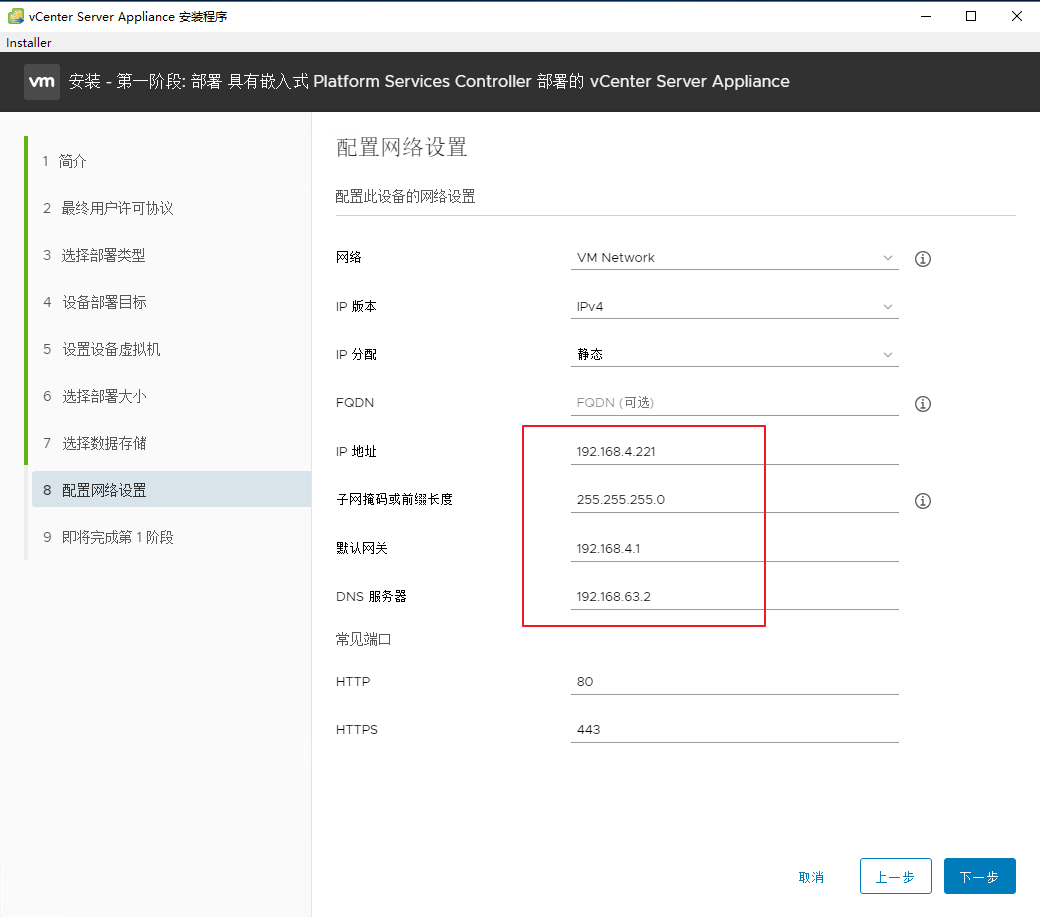
192.168.4.116 hadoop-namenode
192.168.4.135 hadoop-yarn
192.168.4.16 hadoop-datanode1
192.168.4.210 hadoop-datanode2
192.168.4.254 hadoop-datanode3
7.SSH免密码登录(同理将其它节点的公钥追加进来,即:每个节点都拥有其它机器的公钥)
# 一路回车即可,在~/.ssh 目录下回生成id_rsa.pub 文件,将该文件追加到authorized_keys
ssh-keygen -t rsa
cd ~/.ssh
#在三台服务器上执行(此一步可以使用“二.服务器优化”8.SSH免登录置 处理,如果上面已处理,这一步略过,不需要操作)
yum -y install openssh-clients
#在hadoop-namenode-192.168.4.116上
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.4.16
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.4.135
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.4.210
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.4.254
#在hadoop-yarn-192.168.4.135上
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.4.16
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.4.116
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.4.210
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.4.254
#在hadoop-datanode1-192.168.4.16上
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.4.116
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.4.135
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.4.210
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.4.254
#在hadoop-datanode2-192.168.4.210上
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.4.16
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.4.116
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.4.135
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.4.254
#在hadoop-datanode3-192.168.4.254上
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.4.16
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.4.116
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.4.135
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.4.210
8.解压hadoop到指定目录
#下载hadoop安装包
wget http://apache.01link.hk/hadoop/common/hadoop-3.1.1/hadoop-3.1.1.tar.gz
# -C 参数指定解压目录
tar -zxvf hadoop-3.1.1.tar.gz -C /data
mkdir -pv /data/hadoop-3.1.1/dfs/tmp
mkdir -pv /data/hadoop-3.1.1/dfs/name
mkdir -pv /data/hadoop-3.1.1/dfs/data
chown -R hadoop.hadoop /data/hadoop-3.1.1
chmod 755 -R /data/hadoop-3.1.1
rm -f /data/hadoop-3.1.1.tar.gz
9.配置hadoop环境变量
vim ~/.bash_profile
#新增内容如下所示:
export HADOOP_HOME=/data/hadoop-3.1.1
export PATH=$PATH:$HADOOP_HOME/bin
# 让配置立即生效,否则要重启系统才生效
source ~/.bash_profile
10.配置hadoop-env.sh、mapred-env.sh、yarn-env.sh,在这三个文件中添加JAVA_HOME路径,如下
vim /data/hadoop-3.1.1/etc/hadoop/hadoop-env.sh
vim /data/hadoop-3.1.1/etc/hadoop/mapred-env.sh
vim /data/hadoop-3.1.1/etc/hadoop/yarn-env.sh
#新增内容如下所示:
export JAVA_HOME=/data/jdk1.8.0_20
11.配置core-site.xml文件
vim /data/hadoop-3.1.1/etc/hadoop/core-site.xml
#新增内容如下所示(可以配置对应的IP):
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-namenode:9000</value>
<description>namenode的地址</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/hadoop-3.1.1/dfs/tmp</value>
<description>namenode存放数据的目录</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
12.配置hdfs-site.xml文件
vim /data/hadoop-3.1.1/etc/hadoop/hdfs-site.xml
#新增内容如下所示(可以配置对应的IP):
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop-namenode:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop-namenode:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>文件副本数,一般指定多个,测试指定一个</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/hadoop-3.1.1/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/hadoop-3.1.1/dfs/data</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>16m</value>
</property>
</configuration>
13.配置mapred-site.xml文件
vim /data/hadoop-3.1.1/etc/hadoop/mapred-site.xml
#新增内容如下所示(可以配置对应的IP):
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop-yarn:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop-yarn:19888</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/data/hadoop-3.1.1/etc/hadoop,
/data/hadoop-3.1.1/share/hadoop/common/*,
/data/hadoop-3.1.1/share/hadoop/common/lib/*,
/data/hadoop-3.1.1/share/hadoop/hdfs/*,
/data/hadoop-3.1.1/share/hadoop/hdfs/lib/*,
/data/hadoop-3.1.1/share/hadoop/mapreduce/*,
/data/hadoop-3.1.1/share/hadoop/mapreduce/lib/*,
/data/hadoop-3.1.1/share/hadoop/yarn/*,
/data/hadoop-3.1.1/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
14.配置yarn-site.xml文件
vim /data/hadoop-3.1.1/etc/hadoop/yarn-site.xml
#新增内容如下所示(可以配置对应的IP):
<configuration>
<!– Site specific YARN configuration properties –>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-yarn</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop-yarn:8032</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop-yarn:8031</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop-yarn:8030</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop-yarn:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop-yarn:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>flase</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>6</value>
<description>每个任务使用的虚拟内存占物理内存的百分比</description>
</property>
</configuration>
15.通过scp命令将上述修改的文件复制到其它服务器:
scp -r /data/hadoop-3.1.1 hadoop-yarn:/data
scp -r /data/hadoop-3.1.1 hadoop-datanode1:/data
scp -r /data/hadoop-3.1.1 hadoop-datanode2:/data
scp -r /data/hadoop-3.1.1 hadoop-datanode3:/data
16.在hadoop-namenode上进行NameNode的格式化
cd /data/hadoop-3.1.1
./bin/hdfs namenode -format
17.在hadoop-namenode上启动namenode
./bin/hdfs –daemon start namenode
18.在hadoop-yarn上启动resourcemanaer,nodemanager
cd /data/hadoop-3.1.1
./bin/yarn –daemon start resourcemanager
./bin/yarn –daemon start nodemanager
19.在hadoop-datanode1,hadoop-datanode2,hadoop-datanode3上启动datanode,nodemanager
cd /data/hadoop-3.1.1
./bin/hdfs –daemon start datanode
./bin/yarn –daemon start nodemanager
20.通过jps命令可以查看启动的进程
jps
21.通过自带例子测试hadoop集群安装的正确性
cd /data/hadoop-3.1.1
./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar pi 1 2
22.修改C:\Windows\System32\drivers\etc\hosts文件增加下面域名映射
#hadoop-spark大数据
192.168.4.116 hadoop-namenode
192.168.4.135 hadoop-yarn
192.168.4.16 hadoop-datanode1
192.168.4.210 hadoop-datanode2
192.168.4.254 hadoop-datanode3
23.通过管理界面查看集群情况
http://hadoop-namenode:50070 #可以配置对应的IP
http://hadoop-yarn:8088 #可以配置对应的IP
五.安装scala
1.下载解压
wget https://downloads.lightbend.com/scala/2.12.8/scala-2.12.8.tgz
tar -zxvf scala-2.12.8.tgz -C /data
chown -R hadoop:hadoop /data/scala-2.12.8
chmod 755 -R /data/scala-2.12.8
rm -f /data/scala-2.12.8.tgz
2.修改/etc/profile文件
vim /etc/profile
##scala环境变量设置:
export SCALA_HOME=/data/scala-2.12.8
export PATH=$PATH:$SCALA_HOME/bin
#让其立即生效
source /etc/profile
#查看scala版本号
scala -version
六.安装spark
1.Spark安装,分为:
1). 准备,包括上传到主节点,解压缩并迁移到/data/目录;
2). Spark配置集群,配置/etc/profile、conf/slaves以及confg/spark-env.sh,共3个文件,配置完成需要向集群其他机器节点分发spark程序
3). 直接启动验证,通过jps和宿主机浏览器验证
4). 启动spark-shell客户端,通过宿主机浏览器验证
2.解压
tar -zxvf spark-2.3.2-bin-hadoop2.7.tgz -C /data
chown -R hadoop:hadoop /data/spark-2.3.2-bin-hadoop2.7
chmod 755 -R /data/spark-2.3.2-bin-hadoop2.7
rm -f /data/spark-2.3.2-bin-hadoop2.7.tgz
3.配置文件与分发程序
3.1 各个节点上配置/etc/profile
vim /etc/profile
#spark环境变量设置:
export SPARK_HOME=/data/spark-2.3.2-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
#让其立即生效
source /etc/profile
3.2 配置conf/slaves
cp /data/spark-2.3.2-bin-hadoop2.7/conf/slaves.template /data/spark-2.3.2-bin-hadoop2.7/conf/slaves
vim /data/spark-2.3.2-bin-hadoop2.7/conf/slaves
#添加节点如下所示:
# A Spark Worker will be started on each of the machines listed below.
#localhost
#添加节点如下所示:
hadoop-datanode1
hadoop-datanode2
hadoop-datanode3
3.3 配置conf/spark-env.sh
cp /data/spark-2.3.2-bin-hadoop2.7/conf/spark-env.sh.template /data/spark-2.3.2-bin-hadoop2.7/conf/spark-env.sh
vim /data/spark-2.3.2-bin-hadoop2.7/conf/spark-env.sh
#添加内容如下所示;
export JAVA_HOME=/data/jdk1.8.0_20
export SCALA_HOME=/data/scala-2.12.8
export HADOOP_HOME=/data/hadoop-3.1.1
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_WORKER_OPTS=”-Dspark.worker.cleanup.enabled=true -Dspark.worker.cleanup.interval=864000 -Dspark.worker.cleanup.appDataTtl=864000″
export SPARK_MASTER_IP=hadoop-datanode1
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=900M
3.4 重新设置目录归属和授权
chown -R hadoop:hadoop /data/spark-2.3.2-bin-hadoop2.7
chmod 755 -R /data/spark-2.3.2-bin-hadoop2.7
3.5 向各节点分发Spark程序
#进入hadoop-datanode1机器/data/目录,使用如下命令把spark-2.3.2-bin-hadoop2.7文件夹复制到hadoop-datanode2和hadoop-datanode3机器
scp -r /data/spark-2.3.2-bin-hadoop2.7 hadoop-datanode2:/data/
scp -r /data/spark-2.3.2-bin-hadoop2.7 hadoop-datanode3:/data/
3.6 在spark主节点hadoop-datanode1上配置master与master的信任关系
否则有可能报错 “Spark:通过start-slaves.sh脚本启动worker报错:Permission denied, please try again”
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
cat /root/.ssh/id_rsa.pub >> /root/authorized_keys
3.7 管理Spark服务
cd /data/spark-2.3.2-bin-hadoop2.7/sbin
./start-all.sh #启动Spark
./stop-all.sh #关闭spark
jps #验证启动
netstat -nlt #通过netstat -nlt 命令查看hadoop-datanode1节点网络情况
3.8 验证客户端连接
#进入hadoop-datanode1节点,进入spark-2.3.2-bin-hadoop2.7的bin目录,使用spark-shell连接集群
cd /data/spark-2.3.2-bin-hadoop2.7/bin
spark-shell –master spark://hadoop-datanode1:7077 –executor-memory 600m
七.服务脚本管理
1.在hadoop-namenode上
mkdir -pv /root/.script
vim /root/.script/start_hadoop-namenode.sh
#添加内容如下所示:
#!/bin/bash
nowtime=`date –date=’0 days ago’ “+%Y-%m-%d %H:%M:%S”`
/data/hadoop-3.1.1/bin/hdfs –daemon start namenode
echo $nowtime “启动hadoop namenode成功” >> hadoop.log
#授权
chmod 755 /root/.script/start_hadoop-namenode.sh
2.在hadoop-yarn上
mkdir -pv /root/.script
vim /root/.script/start_hadoop-yarn.sh
#添加内容如下所示:
#!/bin/bash
nowtime=`date –date=’0 days ago’ “+%Y-%m-%d %H:%M:%S”`
/data/hadoop-3.1.1/bin/yarn –daemon start resourcemanager
echo $nowtime “启动hadoop resourcemanager成功” >> hadoop.log
/data/hadoop-3.1.1/bin/yarn –daemon start nodemanager
nowtime2=`date –date=’0 days ago’ “+%Y-%m-%d %H:%M:%S”`
echo $nowtime2 “启动hadoop nodemanager成功” >> hadoop.log
#授权
chmod 755 /root/.script/start_hadoop-yarn.sh
3.在hadoop-datanode1,hadoop-datanode2和hadoop-datanode3上
mkdir -pv /root/.script
vim /root/.script/start_hadoop-datanode.sh
#添加内容如下所示:
#!/bin/bash
nowtime=`date –date=’0 days ago’ “+%Y-%m-%d %H:%M:%S”`
/data/hadoop-3.1.1/bin/hdfs –daemon start datanode
echo $nowtime “启动hadoop datanode成功” >> hadoop.log
/data/hadoop-3.1.1/bin/yarn –daemon start nodemanager
nowtime2=`date –date=’0 days ago’ “+%Y-%m-%d %H:%M:%S”`
echo $nowtime2 “启动hadoop nodemanager成功” >> hadoop.log
#授权
chmod 755 /root/.script/start_hadoop-yarn.sh
4.在spark主节点hadoop-datanode1上配置启动服务和关闭服务脚本
4.1 启动服务
vim /root/.script/start_spark.sh
#添加内容如下所示:
#!/bin/bash
nowtime=`date –date=’0 days ago’ “+%Y-%m-%d %H:%M:%S”`
/data/spark-2.3.2-bin-hadoop2.7/sbin/start-all.sh
echo $nowtime “启动spark成功” >> spark.log
#授权
chmod 755 /root/.script/start_spark.sh
4.2 关闭服务
vim /root/.script/stop_spark.sh
#添加内容如下所示:
#!/bin/bash
nowtime=`date –date=’0 days ago’ “+%Y-%m-%d %H:%M:%S”`
/data/spark-2.3.2-bin-hadoop2.7/sbin/stop-all.sh
echo $nowtime “启动spark成功” >> spark.log
#授权
chmod 755 /root/.script/stop_spark.sh




 D
D